In 1997 I started working professionally as a programmer, to the surprise of my family and friends. I really have a masters degree in economics and sociology, majoring in marketing. This, however, felt boring to me. My real interest was art and computers. My brother bought a ZX Spectrum when I was 11 and we spent a lot of time in front of it, writing basic and inputting game code from magazines like Sinclair User. After the Spectrum, I went with Atari, which also was the computer I wrote my master exam on when I graduated from university. I've often wondered if they could ever read that floppy disc...
So when the web came along, I started creating web pages. Art and computers baked into one! Around 1995, I spent my time doing web pages for the organisation I was really supposed to write a marketing plan for. In 1996 I worked in health care, and instead of doing my job as a controller, I worked on an application in MS Access where the wards could do their own financial monitoring. And then I realised it was time to move on. I started my own web company and 6 months later, I was sucked into the blossoming dotcom industry in Stockholm.
In the beginning, I was fascinated by the new industry. The career path seemed clear. You were supposed to start with front end development, considered lowest in rank, move to back end or the data layer and then advance to project management. The companies were young and the people were all the same age, but already split into two teams. Developers, casually dressed and not trusted to meet clients, and project managers, dressed in suits and handling all the external communication. I was especially fascinated by the fact that the 25-year old women with the same engineer exams as the developer blokes were all project managers. Was it because they were the ones who could talk to clients, because they didn't feel comfortable in the developer group or because of the higher status? Almost 20 years later, I don't know.
I went into the industry because I had a great interest in developing applications that would make life easier for people and organisations. I don't have an exam, I've never studied any technology. So the first 10 years, I always felt insecure. I felt like I didn't really belong, I didn't know the correct terms, I didn't dare to push my views forward because I was always being put down by someone who knew more than I did. And it was easy to put me down, since my self confidence was at rock bottom. Because - I was still a developer. 10 years in the industry and still a developer! What's wrong with me?!
And I fell into that trap. The title trap. Am I really only a developer? Didn't I design and build that CMS? Didn't I design and build that betting sportsbook? Am I not really - an ARCHITECT? At least I should be by now. My employer definitely wanted to sell me as an architect, since it meant more money. And wasn't it really strange, not having the ambition to become anything more than a mere developer? To top it off, being a FEMALE ARCHITECT! Wow, I could probably get my own TV-show! So I went along with it. I went for a Microsoft Professional Architect Certificate. And the years following that was the worst years in my working life.
Why that was, I've tried to dissect. Maybe it was me, with my lousy self confidence, feeling I wasn't living up to the standard I should have. Maybe it was the organisations, having different views on what an architect should do. Maybe it was the younger blokes in some places who made my life hell. Maybe it was my feeling of being hired because WE NEED WOMEN IN TECH and I constantly had to prove I was as good as a man. Anyway, I woke up many Monday mornings and thought about doing something entirely different. Like, maybe, work as a waitress or something... Something I could manage.
The thing is, once you're in that position, it's hard to back out of it. You tell your manager you don't want to have that role. They say they're happy with your work and wants to help you move forward instead of back. And you have that bad feeling that if you back out, you're a failure. Because just saying that "In 3 years time, I still want to be a programmer, only much better" isn't really the level of ambition most companies expect.
I could say it's only me, but when I look at my fellow developer contacts on LinkedIn I see Senior Developers, Solution Architects, Team Leads etc etc. And I wonder, for us as an industry where we developers talk so much about self organising teams, joint responsibility, flat organisations... Where did this need to rise above the rest appear? Why do we feel the need to say that we are SENIOR developers?
For my own part, I've left all of that behind. I'm a developer, in an awesome team, where everyone chips in and I never have the need to lead anything anymore. With that I mean I never have the feeling that tomorrow, when I get in at work, I need to know exactly what to do and how because everyone expects that of me. Mob programming have changed all that around for me. We build awesome things together, I contribute with my knowledge and experience as do every individual in the team. And every day, I learn something new. I go home feeling that it has been a good day, I don't work late when the kids have gone to sleep, and I go to work full of energy the next day. And after 20 years of building web sites, I actually think that this is the best time I've ever had. :)
Maybe one day I'll write about this WOMEN IN TECH-bit.
Saturday, 14 November 2015
Wednesday, 11 November 2015
Setting up feature branch deploys using Github, Teamcity and Octopus Deploy
Sooner or later, when you have a website in production, the question arises: how to develop new features without deploying partly built features along with bug fixes? Feature toggles might be the way to go. But that can be tricky to implement, and almost always needs code cleanup after the feature is released.
We decided to try and find a way where we could quickly deploy any given feature branch if we needed to. Since we mob program we mainly work directly in the master branch, but sometimes we do bigger features that need to be looked at or tested outside the team.
There are of course many other ways to solve feature branch deploys, but we wanted to have the manual step to choose what branch to deploy where and with what config.

Now, when we click the Run button for the build, we have to fill in those fields. Sweet!

One thing though! Custom builds in Teamcity can not trigger another build using the Finish Build Trigger. Our solution was to just merge the build and deploy steps into a single build. It took a few hours to discover why the trigger didn't work, and it hurt a bit to get a build consisting of 14 steps, but the show must go on, right?
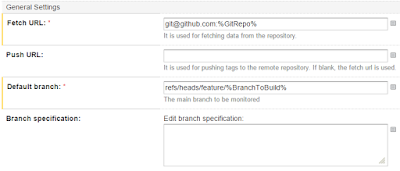
When creating a release, Octopus Deploy automatically looks for the Nuget package with the highest release number. This is not what we want here though. Many builds use the same "Feature"-package id and the release number created might not be the highest one, since the build counter will be different for each build. Luckily, the Octopus plugin gives us a possibility to use the command line options of octo.exe. We have two options we need:
We make extensive use of Step templates to create the building bricks for our deploy processes, it's a brilliant feature. Especially in this case where we want to be able to easily add new Feature deploys.
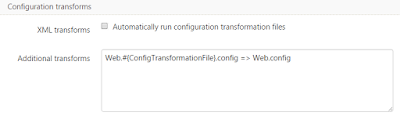
Doing it like this is a fairly simple process. The release gets created in the project belonging to the subdomain chosen in Teamcity. The only thing that actually has to be handled dynamically is receiving the ConfigTransformationFile-variable to decide which config should be deployed.
To be able to receive a variable through octo.exe, two things are necessary:
We decided to try and find a way where we could quickly deploy any given feature branch if we needed to. Since we mob program we mainly work directly in the master branch, but sometimes we do bigger features that need to be looked at or tested outside the team.
Really short version - the quirks
- Custom builds can not trigger another build using the Finish Build Trigger in Teamcity.
- Variables can be passed from Teamcity to Octopus Deploy only if they are set up as prompted variables in Octopus.
- The prompted variables in Octopus Deploy have to be set up directly on the project, not in an included variable set.
Deploy process
What we wanted to achieve was being able to trigger a build manually in Teamcity, by stating:- Which branch to deploy.
- Which config transformation file to use (stage, pre-production, production).
- Which subdomain to deploy to.
There are of course many other ways to solve feature branch deploys, but we wanted to have the manual step to choose what branch to deploy where and with what config.
Teamcity setup
First step was to set up a new build template in Teamcity. We have multiple projects and use build templates extensively to help us set up new builds quickly. The normal builds are quite basic:Step 1 - Build
- Triggered by Github change to a certain VCS root.
- Runs Nuget restore.
- Runs Grunt tasks.
- Builds .Net sln.
- Runs tests.
- Copies minified files from grunt step into package.
Step 2 - Deploy
- Triggered by finishing build in step 1.
- Creates a Nuget spec.
- Packages the artifact from step 1 using the Nuget spec.
- Publishes the Nuget package to Octopus Nuget feed.
- Creates a release in Octopus Deploy and deploys it to stage environment. The Octopus plugin for Teamcity, which is simply a wrapper for octo.exe, works like a charm.
Set up custom build
To get the parameters in Teamcity that you require for each build, just set them up as required prompts. These can be configured as text fields, select lists etc. For our BranchToBuild we used text field, but for the Subdomain to deploy to and the ConfigTransformFile to use we added select lists.
Now, when we click the Run button for the build, we have to fill in those fields. Sweet!
One thing though! Custom builds in Teamcity can not trigger another build using the Finish Build Trigger. Our solution was to just merge the build and deploy steps into a single build. It took a few hours to discover why the trigger didn't work, and it hurt a bit to get a build consisting of 14 steps, but the show must go on, right?
Get the correct code from Github
In our normal builds we've configured the VCS root to look for changes in the master branch of a certain repo, or pull requests. In the feature branch we of course want the code to be fetched from the branch we input when we trigger the build. Easy thing, just open the VCS root and use the BranchToBuild parameter in the Default branch-field.
Naming of deploy Nuget package
This one we thought a bit about. We decided to go with a "Feature"-package id, instead of naming the packages according to their different application names like we normally do. The reason for this is that Octopus Deploy needs to be set up to look for a certain Nuget package id. By naming all the packages "Feature" we could set up five identical and application agnostic Octopus Deploy projects.Creating an Octopus Deploy release
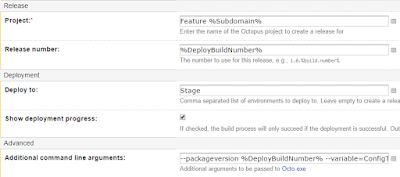
We want to deploy our feature to the Octopus Project that corresponds to the subdomain we chose in the first step. The Octopus projects are named Feature F1 to Feature F5 so we just use the parameter Subdomain to set the correct project. As release number we use the parameter DeployBuildNumber which is simply the concatenated build counter, product and branch name, e g '1.0.9-Product-Testbranch'.
When creating a release, Octopus Deploy automatically looks for the Nuget package with the highest release number. This is not what we want here though. Many builds use the same "Feature"-package id and the release number created might not be the highest one, since the build counter will be different for each build. Luckily, the Octopus plugin gives us a possibility to use the command line options of octo.exe. We have two options we need:
- --packageversion %DeployBuildNumber% tells Octopus to use the specified release of the package instead of the default one.
- --variable=ConfigTransformationFile:%ConfigTransformationFile% sets the variable ConfigTransformationFile in Octopus to the specified value, which is the config file stated in our input parameters.
Octopus Deploy
In Octopus, we normally use a rolling deploy, taking the machines out of the load one by one, configuring IIS, setting up firewall rules, deploying, smoke testing and putting them back in the load if everything succeeds. Now, all we want to do is deploy the given "Feature"-package to a certain IIS website using the given transformation file.We make extensive use of Step templates to create the building bricks for our deploy processes, it's a brilliant feature. Especially in this case where we want to be able to easily add new Feature deploys.
Deploy process setup
Our set up in Octopus Deploy is one project for each available feature deploy subdomain, F1 to F5. This could be changed to just using one and dynamically setting the hostname and IIS to deploy to, but we wanted to have a dashboard in Octopus where we could see what feature is currently deployed where.Doing it like this is a fairly simple process. The release gets created in the project belonging to the subdomain chosen in Teamcity. The only thing that actually has to be handled dynamically is receiving the ConfigTransformationFile-variable to decide which config should be deployed.
To be able to receive a variable through octo.exe, two things are necessary:
- The variable has to be set up as a prompted variable.
- The variable has to be set up directly in the project, it will not work if it's in an included variable set.
Saturday, 31 October 2015
Teaming up and moving onto the happy path
This is a story I think all developers know. A new team, starting a greenfield project under seemingly perfect conditions. An agile coach, an organisation ready for change and another team paving the way with a similar solution. And still, a few months down the line; a complex solution, broken deadlines and a feeling that things weren't moving in the right direction.
Not that things were going badly, they just didn't go as smooth as we hoped. And the team was very aware of what the problem was. We had inherited an architecture that we didn't feel comfortable with. Too much code was shared between applications and the complexity of the solution made us uncomfortable. We tried to solve our tasks the best way we could. But we did it alone, since the stress of missed deadlines kept us away from pair programming.
So. What to do to fix this situation before things went too far? We decided to change things around and break some patterns.
So we discussed this in the team and came to an easy decision: we informed the organisation that our team no longer had an appointed architect. Meeting requests could be sent to the team as a whole and we promised that one or more of us would attend. Most of the times, at least two of us go to those meetings, one who knows the area and one who wants to learn. This has resulted in a situation where the team as a whole is informed of everything. Really, everything!
This turned out to be the real turnaround for us as a team. The result of that week was so good, so when the next week came, we decided to keep on sitting together. At first, we didn't really have a place to sit, so each day we found available conference rooms and booked them. We set a timer for 20 minutes and took turns at the keyboard. We as a development team made good progress, but we were practically invisible for the rest of the project team and organisation. So the next step was to make it official.
at the same time,
in the same space,
and on the same computer.
Or in short, one driver at the keyboard and many navigators.
Instead of being 2 months ahead of development, we'll all be working on the same feature. The ideas from last week will be put in production next week. We'll eliminate waste and go directly to what we do best, code it, test it, tweak it. It's going to be a very interesting journey. :)
Not that things were going badly, they just didn't go as smooth as we hoped. And the team was very aware of what the problem was. We had inherited an architecture that we didn't feel comfortable with. Too much code was shared between applications and the complexity of the solution made us uncomfortable. We tried to solve our tasks the best way we could. But we did it alone, since the stress of missed deadlines kept us away from pair programming.
So. What to do to fix this situation before things went too far? We decided to change things around and break some patterns.
Shared responsibility
When the team started up, I got the inofficial title of architect. This is a title I don't like, for many reasons. The architect gets called to all the meetings, never have time to do anything else and sits on all the information that the team needs. A bit harsh, maybe, but this is my experience after having had this title the last 3-4 years. The way I see it, the more people who knows what we're supposed to build, the better. And with 6 experienced and informed developers in a team, the architecture will improve in every little corner of and around the solution.So we discussed this in the team and came to an easy decision: we informed the organisation that our team no longer had an appointed architect. Meeting requests could be sent to the team as a whole and we promised that one or more of us would attend. Most of the times, at least two of us go to those meetings, one who knows the area and one who wants to learn. This has resulted in a situation where the team as a whole is informed of everything. Really, everything!
New project - new ideas
After the summer vacation, the team was supposed to start a new project and build a third website. The project kicked off with a hack week. During that week, we decided to sit together and get the foundation of the new site up and running. We wanted to simplify our solution and build something that we all felt comfortable with.This turned out to be the real turnaround for us as a team. The result of that week was so good, so when the next week came, we decided to keep on sitting together. At first, we didn't really have a place to sit, so each day we found available conference rooms and booked them. We set a timer for 20 minutes and took turns at the keyboard. We as a development team made good progress, but we were practically invisible for the rest of the project team and organisation. So the next step was to make it official.
Mob programming
So one morning, we got an OK from our manager to use a couple of the tables in the middle of the office landscape. We put them together and installed a mob programming station. One big TV, a smaller screen and the dock for the laptop where the mob programming timer is displayed. A wireless mouse and keyboard together with all our mobile test devices completed the equipment. And there we've been ever since.What is mobprogramming?
All the brilliant people working on the same thing,at the same time,
in the same space,
and on the same computer.
Or in short, one driver at the keyboard and many navigators.
A normal day
- Who's here today?
- Dock one of our laptops at the mob station.
- Set the timer on 12 minutes each, we use the handy Agility Timer.
- Quick summary, where did we leave off yesterday?
- Start coding!
And the navigators do what?
- Real time code reviewing.
- Googling.
- Testing on mobile devices.
- Looking at upcoming tasks so we're not missing strategic decisions.
- Discussing design and architecture.
- Making decisions together with the driver.
But how can that be efficient?!
It's not... If we're looking to maximize lines of code written. But we should all be beyond thinking that is a good thing by now, right? However, if we want to deliver working features with good quality and short lead times, this might be the way to go.Short lead times?
Yes. If we have a working setup for continuous delivery, and everyone is working on the same feature, when we have no pull requests or merge issues, a feature can go from idea to production in the shortest possible time.Good quality?
This section could go on forever. The positive effect we've seen in this area is huge. :)- The team is coding, reviewing, analyzing, designing and testing simultaneously.
- We constantly learn together and from each other; technically, domain wise and valuable tips and tricks regarding tools and processes.
- Knowledge sharing. Everyone does everything, from CSS to build scripts. If we don't know the area or feel comfortable, we lessen the time at the keyboard or just pass it over. But we still learn and become better developers.
- The team considers more design options than a coder working alone would do. This typically results in less complex code.
- The amount of unused, duplicated, unnecessary code is at a minimum.
- We now have an architecture that's alive, flexible and thought through on all levels of our solution.
What have we gained?
- Focus! No context switching. We do one task at the time.
- Continuity! We're not dependent on any one individual. No one has to work from home when they're ill to make a deadline.
- Communication! With each other and others. Everyone is welcome to come over and talk to us at our table. It's easier for others, since they now only have one place to come to.
- Fewer meetings! One or two of us goes to a meeting, the rest keep on working. The team still gets all the info when the meeting attendees get back.
- No setup time for new team members! Productivity from day one.
- No idle time! We never get stuck, we can always keep on moving.
- Teambuilding 101! Coding together 9 - 5 builds a team in a way no AW can do...
- More fun! Which means more motivating. Which means we're more productive.
How can we make it work?
Some basic things are needed in this process. They might not be there from the beginning, but to be successful I think you need to get there.- Trust. Within the team and from the organisation.
- A shared objective. Agree on what you want to achieve by working this way.
- Respect for the competence and experiences of your team mates.
- Humility. We all know it, right? "There's no I in team". ;)
Do I miss coding alone?
No. And I don't want to go back to that. When I code at home, I code alone. But I never do work stuff at home anymore, just coding for fun.Changed team - changed organisation
This is actually the amazing part of our team's transition. The organisation changes with us. The project we are setting out to do next was originally set up as a traditional IT-project. Now we're changing it so the whole team, including business analysis, design and UX will work much more closely.Instead of being 2 months ahead of development, we'll all be working on the same feature. The ideas from last week will be put in production next week. We'll eliminate waste and go directly to what we do best, code it, test it, tweak it. It's going to be a very interesting journey. :)
Saturday, 31 January 2015
Viewing local site from other computers on the network
This easy solution is turning out to be a huge convenience for me. I run Windows as a VM on my Mac using Parallels Desktop. I want the Windows installation to be as clean as possible, not having to install a lot of browsers to be able to check my code and so forth.






The Mac OS is where I normally do things, I keep all my non .Net code there and all the developer utility tools I need. So to use the browsers on my Mac side to view what I'm working on in my Windows VS dev environment, this is what I do.
I just use the built in IIS Express while working. This means my settings for the web project in VS looks like this. A random portnumber is given for the localhost. To find this info, right click your web project and choose 'Properties'.
This results in a nice webpage showing up at http://localhost:2686 when i start and run the site.
It also results in the following configuration being made in the applicationHost.config file for IISExpress. This is the part describing which website can be reached on which address. The applicationHost.config is cleverly hidden, usually at {youruseraccount}/Documents\IISExpress\config. You need to open it as an administrator to be able to save your changes.
Under the <sites>-node you find all the sites currently configured for your IISExpress. The interesting part right now is the binding configuration. This one tells you the site can be found at localhost:2686. That seems about right. But the Mac host, or any other computer on your network can't call localhost:2686 to see the site, they'd just be ending up on their own localhost of course. So this is what we need to fix.
The pattern for the binding is <ipnumber>:<port>:<localhost>. I want to keep the current localhost:2686, that's nice. But I want to add a new binding making sure I can view the site from my Mac. And since I'm calling the windows localhost with win.localhost in other contexts, I add the following line.
Now, to be sure Visual Studio can use this binding, it has to be run in administrator mode. Just start the site up and go to your other machine...
And look at that! Just as beautiful on a Mac. Now... A few things need to be said. The reason I can write win.localhost:2686 on my Mac is because I have that IP-number mapped in my hostfile, like this:
10.211.55.3 win.localhost
And, another reason is that I have opened the Firewall in my VM for incoming calls from the Mac. So those things need to be fixed as well.
If you want to access the localhost from the outside via the IP-number, all you have to do is change the binding in applicationHost.config to the IP-number of your computer on the internal network. Like this, in my case:
Monday, 5 January 2015
Step one - A simple Elastic Search Repository using NEST
So, I now have Elastic Search set up on my Mac and decided to build an API using .Net and Nancy that will serve as an inventory service for the cars in my Car Rental-solution. I've made sure I can call the Elastic Search instance using the address mac.localhost:9200.
The first thing I want to do is to create a kind of repository wrapping Elastic Search, and tests to make sure everything works. But since I really wanna do my solutions teeny tiny, I don't want to do that in a separate project but in the Nancy App itself. Which makes the first step creating the Nancy App that will hold the API.
Nowadays, Nancy comes with some nice project templates for Visual Studio. Just go into Tools >> Extensions and updates to download them.
And now you find them together with all the normal Project templates:

I'm trying hard to do things as simple as possible to start with, which for instance means I try to avoid interfaces unless I see the clear need, meaning either several implementations of a common contract or the need to mock a dependency for unit testing. Here, I see the need to do the latter so I start with a simple ICarRepository interface:
public interface ICarRepository { string Save(Entities.Car car); Entities.Car Get(Guid id); bool Delete(Guid id); IEnumerable<Entities.Car> List(); IEnumerable<Entities.Car> Search(string query); }
And as you see, not a trace of generics. Cause this is a small API serving only cars. :)
Now, next step is to implement this contract in an ElasticSearchCarRepository. And to do that, I need an Elastic Search client for .Net.
Now, next step is to implement this contract in an ElasticSearchCarRepository. And to do that, I need an Elastic Search client for .Net.
NEST
The client I've chosen to use is NEST, which seems to have all the basic functionality I could possible want for a simple application. It's one of the two official ES clients, the other being the more low level Elasticsearch.net, which NEST actually uses internally. NEST has a nice strongly typed Query DSL which makes queries against Elastic Search quite easy. To use NEST, just install the Nuget package.
All that is needed to start indexing and querying Elastic Search with NEST is to create an ElasticClient and start using it as the simple examples below show. The "cars"-string is the name of the index targeted by the client.
elasticClient = new ElasticClient(new ConnectionSettings( new Uri("http://mac.localhost:9200"), "cars")); elasticClient.Index<Entities.Car>(car); elasticClient.Search<Entities.Car>(s => s.QueryString(query))
Since the client is threadsafe I choose to inject it into the repository. Doing that lets me change the client for the tests I'll write so I can test the repository using a testindex that I can play with any way I want to without worrying about destroying real data.
The ElasticSearchCarRepository
The first version of the repository ends up looking like this.public class ElasticSearchCarRepository : ICarRepository { private readonly ElasticClient _elasticClient; public ElasticSearchCarRepository(ElasticClient elasticClient) { _elasticClient = elasticClient; } public string Save(Entities.Car car) { var result = _elasticClient.Index(car); return result.Id; } public Entities.Car Get(Guid id) { var result = _elasticClient.Get<Entities.Car>(id.ToString()); return result.Source; } public bool Delete(Guid id) { var result = _elasticClient.Delete<Entities.Car>(id.ToString(), x => x.Type("car")); return result.Found; } public IEnumerable<Entities.Car> List() { var result = _elasticClient.Search<Entities.Car>(search => search.MatchAll()); return result.Documents; } public IEnumerable<Entities.Car> Search(string query) { var result = _elasticClient.Search<Entities.Car>(search => search.QueryString(query)); return result.Documents; } }
The only thing really interesting here is the id. Elastic Search creates it's own string id if you don't provide it with a specific id when indexing documents. My car entity already has a Guid id that I want to use. This is possible with a simple mapping in the entity class:
[ElasticType(IdProperty = "CarId")] public class Car { [ElasticProperty(Index = FieldIndexOption.NotAnalyzed)] public Guid CarId { get; set; } public string Make { get; set; } public CarType CarType { get; set; } public int DoorCount { get; set; } public int BagCount { get; set; } public bool HasAirCondition { get; set; } public TransmissionType TransmissionType { get; set; } public decimal RentalPricePerDay { get; set; } public string Currency { get; set; } }
The IdProperty on the class tells Elastic Search which property to use as id. And since this is a Guid, we want to make sure ES does not analyze the field, in which case it would split the guid into several strings using the dash as a delimiter.
Another thing worth mentioning here is that I use two enums. NEST sends these values to ES as the integer values. It works well and the enum gets nicely set again when serializing documents, but I'd rather have the string value in ES for those cases when I just wanna look at the data directly. To do this, I have to set the proper converter when creating the client, like so:
public static ElasticClient CreateElasticClient() { var uri = new Uri(ConfigurationManager.ConnectionStrings ["ElasticSearch"].ConnectionString); var settings = new ConnectionSettings(uri, "cars"); settings.AddContractJsonConverters(type => typeof(Enum).IsAssignableFrom(type) ? new StringEnumConverter() : null); return new ElasticClient(settings); }
Testing the repository
To test the repository out I create a simple class library project and import xUnit.Net as a Nuget. There are some different options on running xUnit-tests. I use Resharper, where the option is available as an extension. Other runners are available via Nuget.xUnit has a nice and easy way to share context between methods, meaning setup and teardown methods. By creating a fixture-class that inherits from IDisposable, you can put your setup in the constructor and your teardown in the Dispose-method. What I do here is that I create the repository in the fixture-class, using a client targeting a "cars_test"-index. In the Dispose-method, I just delete that index. It's only there for testing so it's ok.
public class ElasticSearchFixture: IDisposable
{
private readonly ElasticSearchCarRepository _repository;
private readonly ElasticClient _elasticClient;
private const string IndexName = "cars_test";
public ElasticSearchCarRepository Repository
{
get { return _repository;}
}
public ElasticSearchFixture()
{
_elasticClient = CreateElasticClient();
CreateTestIndex();
_repository = new ElasticSearchCarRepository(_elasticClient);
}
private ElasticClient CreateElasticClient()
{
var uri = new Uri(ConfigurationManager.ConnectionStrings
["ElasticSearch"].ConnectionString);
var settings = new ConnectionSettings(uri, IndexName);
settings.AddContractJsonConverters(type =>
typeof(Enum).IsAssignableFrom(type)
? new StringEnumConverter()
: null);
return new ElasticClient(settings);
}
private void CreateTestIndex()
{
DeleteIndex();
_elasticClient.CreateIndex(IndexName, x => x
.NumberOfReplicas(1)
.NumberOfShards(1));
}
public void Dispose()
{
DeleteIndex();
}
private void DeleteIndex()
{
_elasticClient.DeleteIndex(IndexName);
}
}
With the fixture in place, I create my test class and can now test if my favourite car can be saved. The fixture class gives me access to the repository and takes care of cleaning up the test data afterwards.
public class ElasticSearchCarRepositoryTests :
IClassFixture<ElasticSearchFixture>
{
private readonly ElasticSearchFixture _fixture;
public ElasticSearchCarRepositoryTests(ElasticSearchFixture fixture)
{
_fixture = fixture;
}
[Fact]
public void Save_Should_Return_Id_Of_Indexed_Car()
{
// given
var carId = Guid.NewGuid();
var car = CarBuilder.CreateCar()
.WithId(carId)
.WithMake("Ford Focus")
.WithCarType(CarType.Premium).Build();
// when
var result = _fixture.Repository.Save(car);
// then
result.Should().Be(carId.ToString());
}
}
Very easy first step. With loads of stuff missing. Error handling, logging will come later. But next step is to get the Nancy API up and running with tests. And make everything async.
Code, in one state or another, can be found at github.com: https://github.com/asalilje/CarAPI :)
Thursday, 1 January 2015
Now where is that localhost..?
Running Parallels desktop on my MacBook, I figured I wanted to add as little as possible to my Windows installation. Just the necessary things to be able to do .Net development. Visual Studio and SQL Server. As to other databases, I should be able to use the instances already installed on my Mac.
So how to call the localhost of the other OS? Well, not too hard really. Since they're both on a shared network, I should just be able to use the IP-adresses. So first, we need to find them.

Now you can go into the Apple menu >> System preferences >> Network and find the IP-address of the host under the Parallels network provider.

To check if this works, I started up a node server on my Mac, on localhost:4000.

I went in to my Windowsinstallation and tried to call it with the IP-number 10.211.55.2.

Great success! But of course, I don't want to remember that IP-number. So let's edit the hosts-file. And as always, when editing system files, don't forget to run notepad or whatnot as an administrator. The hosts-file, if you managed to avoid it this far, is located in C:\Windows\System32\drivers\etc.


Now go back to the Mac and find the hosts-file under /etc. Add the following line to the file:
So how to call the localhost of the other OS? Well, not too hard really. Since they're both on a shared network, I should just be able to use the IP-adresses. So first, we need to find them.
Finding the IP-address for the Mac host and using it on Windows
Go into the Parallels Desktop menu >> Preferences. Click the tab Advanced and then Network: Change settings. Check the box 'Show in System Preferences'.
Now you can go into the Apple menu >> System preferences >> Network and find the IP-address of the host under the Parallels network provider.
To check if this works, I started up a node server on my Mac, on localhost:4000.
I went in to my Windowsinstallation and tried to call it with the IP-number 10.211.55.2.
Great success! But of course, I don't want to remember that IP-number. So let's edit the hosts-file. And as always, when editing system files, don't forget to run notepad or whatnot as an administrator. The hosts-file, if you managed to avoid it this far, is located in C:\Windows\System32\drivers\etc.
Add the following line to the file:
10.211.55.2 mac.localhost
Save it and you should now be able to call the service with mac.localhost instead. Yay!
Finding the IP-address for the Windows guest and using it on Mac
As you probably guess, you do the same thing. To get the IP-number for the Windows guest, go into Windows, start a Command window and type ipconfig. Look for the IPv4 Address.
Now go back to the Mac and find the hosts-file under /etc. Add the following line to the file:
10.211.55.3 win.localhost
And now you should be able to call the windows localhost from Mac using win.localhost.
ElasticSearch issue
After running Elastic Search on my Mac I wanted to use that instance for my Nancy API I was building on Windows. Since Elastic Search was running on localhost:9200 on the Mac, I assumed the above solution would work without problems. But nope, I just got a Website not found response when I tried to access mac.localhost:9200 in the browser.
Since everything worked with my node server it seemed there wasn't an issue about firewalls or security. I tried some CORS-configuration for a while, thinking that might be the problem. It definitely seemed to have something to do with the Elastic Search configuration and setup.
After quite a long while I found the thing. The Elastic Search config file elasticsearch.yml had the entry network.host: 127.0.0.1. Apparently this entry didn't care about the parallel network adapter at all. So I simply changed the entry to use that IP instead: 10.211.55.2 and restarted Elastic Search.
But wait! Now it works perfectly calling mac.localhost from Windows but I can't call localhost:9200 from the Mac! So another trip into both of the hosts files.
Now I have this in Windows:
10.211.55.3 win.localhost
10.211.55.2 mac.localhost
And this in Mac:
10.211.55.2 mac.localhost
10.211.55.3 win.localhost
All is well and I can develop my .Net-stuff and call services on the Mac. Very neat. I haven't tried the other way around yet, that might be a blogpost for another day.
Subscribe to:
Posts (Atom)